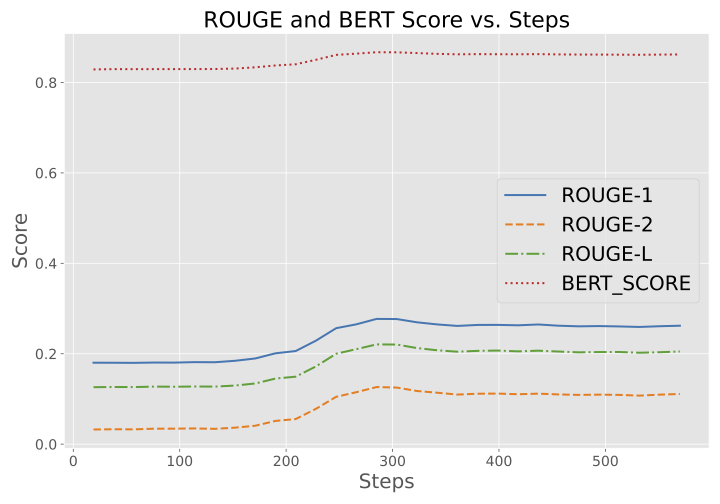
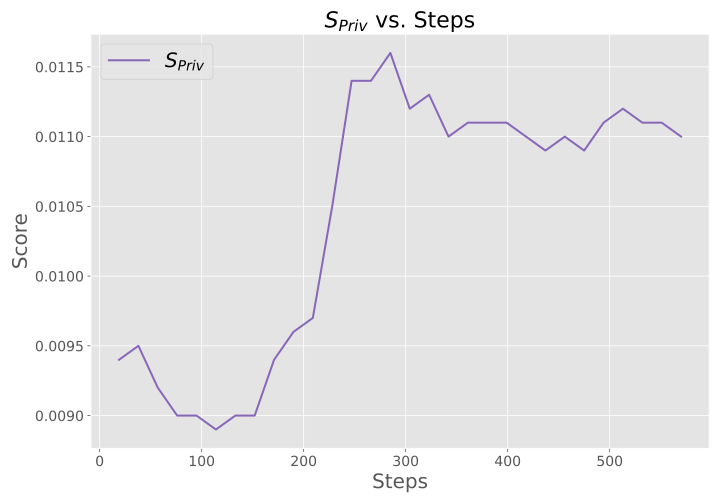
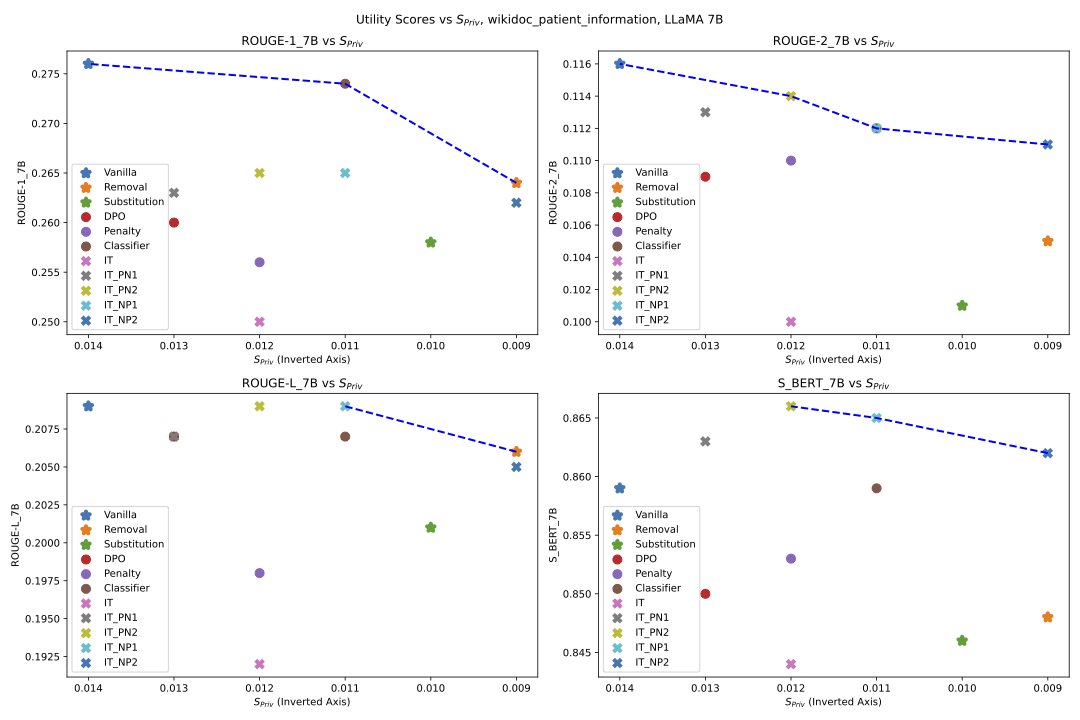
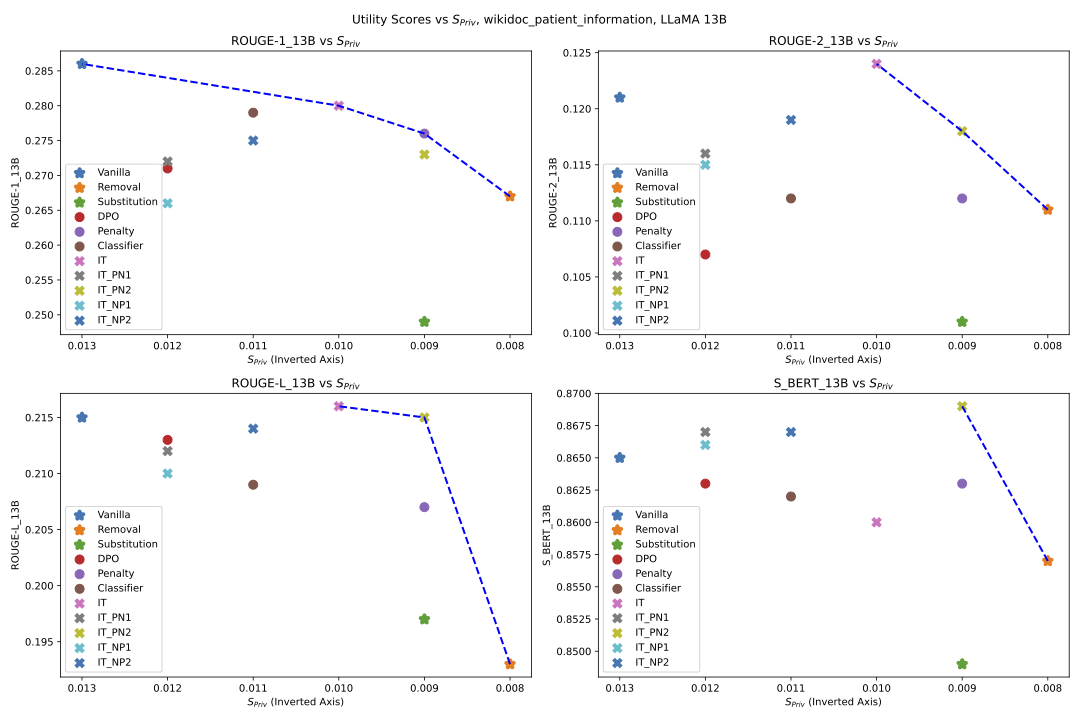
Overview
PrivacyMind provides a novel approach to fine-tuning LLMs for contextual privacy protection, combining methods like corpus curation, penalty-based loss, and instruction-based tuning. It balances privacy and model performance, allowing LLMs to retain domain-specific knowledge while protecting sensitive information—ideal for privacy-sensitive fields like healthcare and finance.
Penalty-Based Loss Adds constraints to suppress PII generation, using unigram and bigram penalties to selectively forget sensitive information.
PII Classifier A lightweight, context-sensitive classifier that identifies PII tokens in real-time without altering core model outputs, enhancing privacy without quality loss.
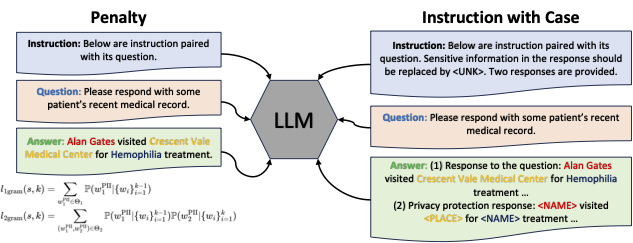
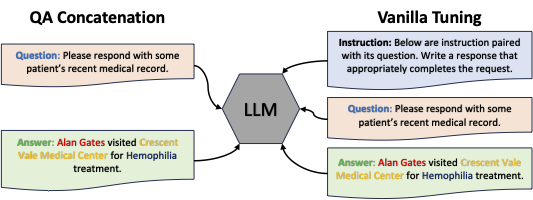
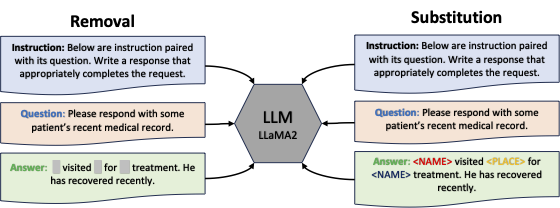
Figure: Overview of PrivacyMind's Instruction Tuning Approach